kafka消费者编程模型
分区消费模型
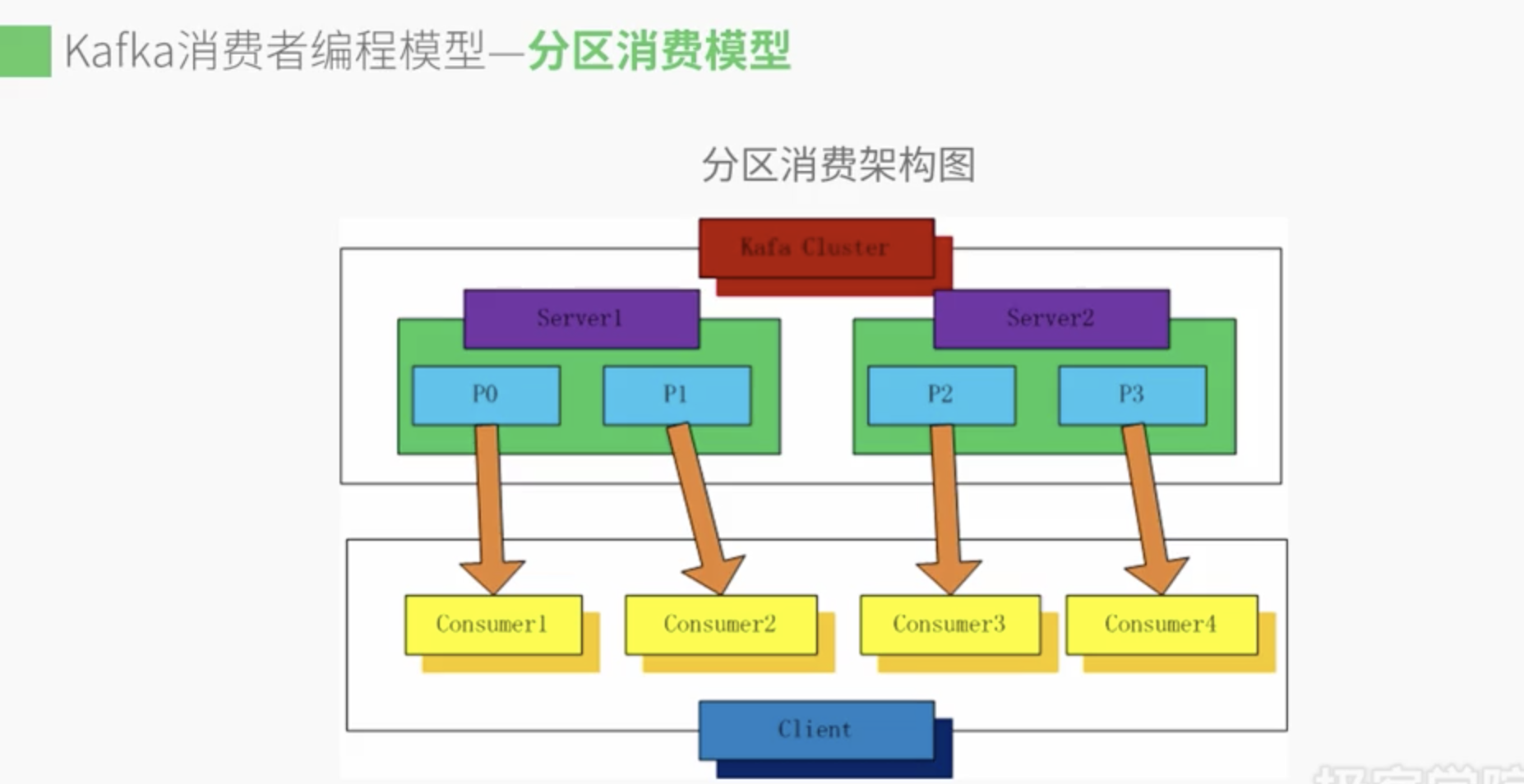
每个Consumer对应一个partition分区,一对一关系
分区消费伪代码描述
main()
获取分区的size
for index = 0 to size
create thread(or process)consumer(index)
第index个线程(进程) consumer(index)
- 创建到kafka broker的连接:KafkaClient(host,port)
- 指定消费参数构建consumer: SimpleConsumer(topic,partitions)
- 设置消费offset:consumer.seek(offset,0)
- while True
消费指定topic第index个分区的数据
处理
记录当前消费offset
提交当前offset(可选)
(客户端默认帮助自动提交偏移量)
组(Group)消费伪代码描述
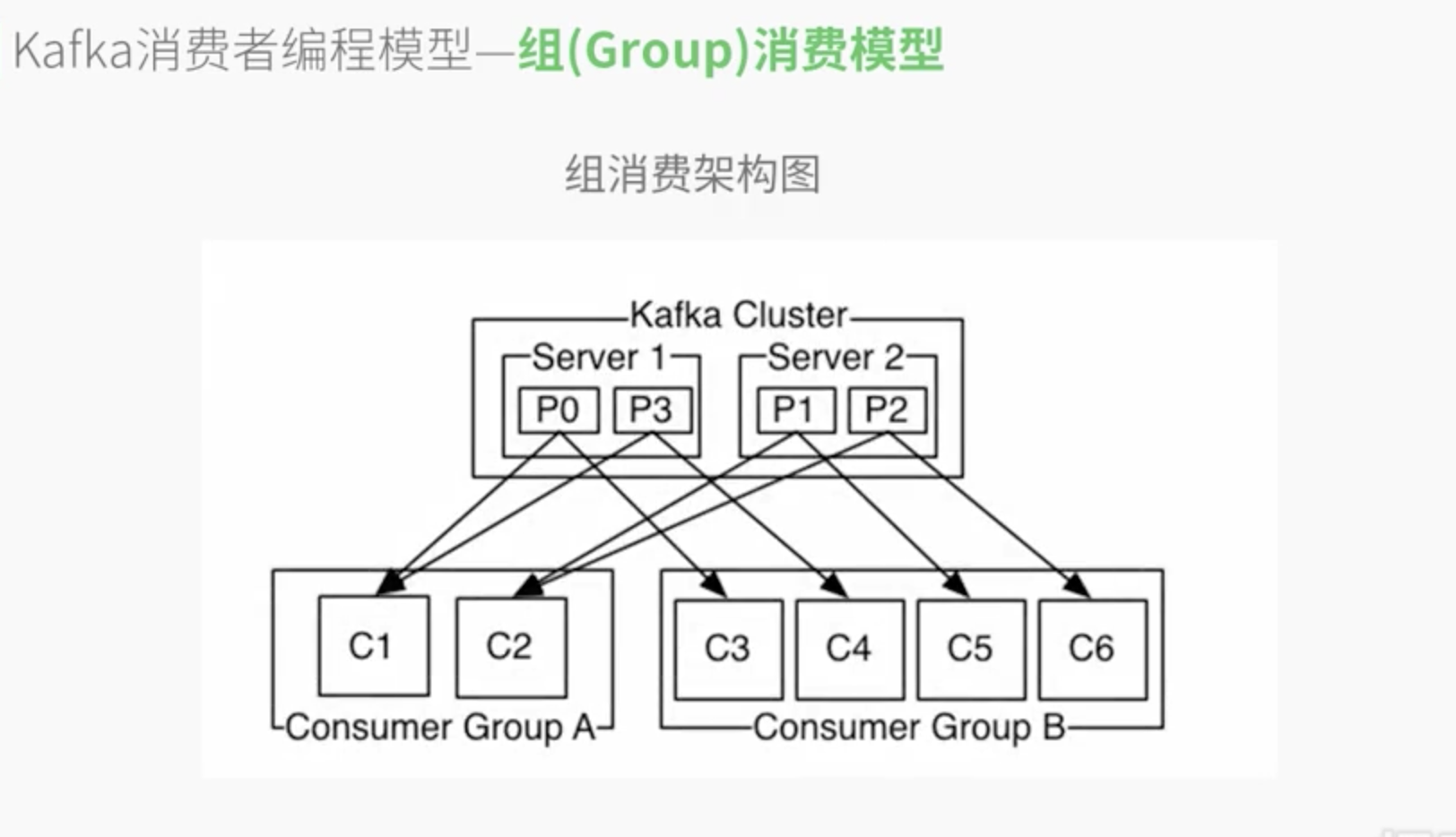
main()
设置需要创建的流数N
for index = 0 to N
create thread(or process)consumer(index)
第index个线程(进程)
consumer(index)
- 创建到kafka broker的连接:KafkaClient(host,port)
- 指定消费参数构建consumer: SimpleConsumer(topic,partitions)
- 设置从头消费还是从最新的消费(smallest或largest)
- while True
消费指定topic第index个分区的数据
处理
(offset会自动提交到zookepper,无需我们操作)
两种消费模型对比
分区消费模型更加灵活但是:
- 需要自己处理各种异常情况
- 需要自己管理offset(以实现消费传递的其他的语义) 组消费模型更加简单,但是不灵活:
- 不需要自己处理异常情况,不需要自己管理offset;
- 只能实现kafka默认的最少一次消息传递语义;
语义
1. At most once 消息可能会丢,但绝不会重复传输
2. At least one 消息绝不会丢,但可能会重复传输
3. Exactly once 每条消息肯定会被传输一次且仅传输一次